






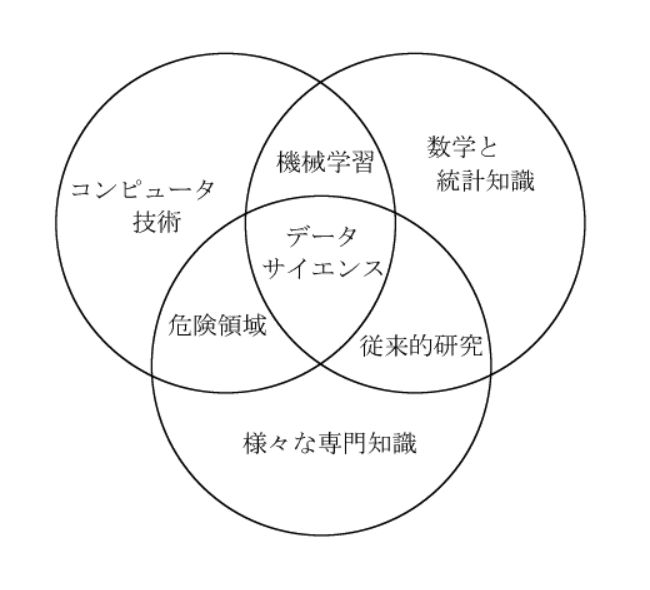
データサイエンスというと、よく取り上げられるベン図(Conway, 2013)があります。それは、「数学と統計知識」と「様々な専門知識」と「コンピュータ技術」に共通するものがデータサイエンスだというものです。概念のイメージとしてはなかなかよく出来たベン図なので、結構よく使われます。データサイエンスには、モデル設定やデータ処理のために数学や統計学の知識が必要だし、得られたデータを理解するために様々な専門知識も必要だし、当然コンピュータを使ってプログラミングやソフトウェアを動かすためにコンピュータ技術も必要だ、となります。
また、データサイエンスをデータの流れに関して考えてみると、
(1)データの収集、前処理、そして調査や吟味、
(2)データの表現や変換、
(3)データを用いた計算、
(4)データに対するモデリング、
(5)データの視覚化とその説明、
(6)データサイエンスに関連する科学、
という分解が可能でしょう(Donoho, 2017)。これはデータを得る段階から最終的に分析結果から新しい知見を得るまでの流れとなります。素のデータはそのままでは扱いにくいので、意外と思われるかも知れませんが、データをきれいにするという(1)(2)の段階がとにかく重要です。
もう少し標語的なデータサイエンスの定義に関しては、統計学者の柴田里程先生(2018)が「データに関するなぜを追求するサイエンス」と提案されています。データに関するなぜを追求するために、まずデータの総体的な理解が基本となります。このことは, データを的確にとらえ理解することの助けともなります。試行錯誤的なアプローチや様々な統計モデルの適用を行う中で、どのようにしたらデータから新たな価値を発見できるか、という指針が得られるときがあります。このようにして得られた発見が、新しい価値創造に繋がっていきます。
データからの価値創造のためにも、まず相関関係を求めるのが基本となります。相関関係はあくまでも線形関係における関連性を見ていますので、相関関係から因果関係を求めることが出来れば、今までの知見とは異なるデータからの発見を得ることが出来るでしょう。因果関係というと、ヒュームに代表されるような哲学的な因果関係を思い浮かべるかも知れませんが、研究室では特に統計的因果推論という枠組みからのアプローチもしています。統計的因果推論とは、反実仮想というモデル設定において、処置を行った時と行わなかった時の差である因果効果を推定するというものです。
ビッグデータ、データサイエンス、AIなどの用語でまとめて語られることが多いですが、機械学習、ディープラーニングや統計学のどの領域においても、今後求められるものは価値創造ではないでしょうか。